
つまり「終わったコンテナ」。
以前からうすぼんやりと考えて来た危惧が、すこしはっきりと見えてきた。
もうそろそろハッシュ(テーブル)以外の手段の連想配列の実装手段を本格的に模索するべきではないか、と。
そのデータ構造は、君の魂を差し出すに足るものかい?
連想配列(Associative array)がコレクション(Collection)、すなわち数多のデータ構造をまとめるデータ構造としての覇者となったのはもはや疑いようがない事実でしょう「配列で実装されるデータ構造ではなくて、配列を実装するデータ構造でありたい」という願いはエントロピーを超え、JavaScriptやPHPで結実したのは先日見たとおりです。
その連想配列の実装手段はいくらでもあります。B木も、二分木も、あるんだよ。キーと値のペアを並べただけの配列やリストだって立派な連想配列ですが、それでは値にアクセスする都度線形探索しなければなりません。二分探索木ですらO(log(n))なところに登場したのが、配列と同じくO(1)アクセスをものにしたハッシュテーブルでした。awkで先鞭をつけperlで人気が爆発したそれが連想配列の別名となったのは「お手柄だよ、Wall」なのですが、おかげで他の実装方法が「特殊化」してしまったことも否めません。なにせ連想配列があれば事実上他のどんなデータ構造もそれを使って実装できるのですから。一番の問題がコストなのですから、時間コストが圧倒的に安価で空間コストもぼちぼちという「安価な連想配列」であるハッシュテーブルにとってかわるデータ構造を探すより、連想配列が"純"配列ほど気楽に使えることを前提にプログラムを書きまくった方が早く書けて楽しいというものです。 perl -nle '$seen{$_}++ }{ print for sort keys %seen' が sort | uniq の代わりになることに私は今でも感動します。
O(1)でなんて、あるわけない
しかし本当のところ、連想配列の要素アクセスがO(1)というのは厳密ではないのは知る人ぞ知るところです。ハッシュ衝突がおきればO(n)にだってなりうるんだよというのが今回のhashdosの教訓ではありますが、Perlはもう9年も前にVersion 5.8.1でハッシュシードの乱択化により解決していました。しかしそのPerlでさえクリアーできない問題がまだ残っています。
ハッシュ関数の計算速度はキーの長さkに対してはO(k)にならざるを得ないということです。
そう。キーそのものだってbyte列なのですよ。長さがkならO(k)です。それでもkが小さければこの点はOk。今日日ポインターですら8byteもあったりします。'dankogai'がすっぽり収まります。
しかし先ほどの perl のワンライナーをもう一度見返してください。ここでキーに入るのは一行分のテキストまるごと。これほど長いキーなら「添字の数値のようにお気楽に」とはいかなくなるはずなのではないか…
というわけで、実験してみた結果が、以下です。
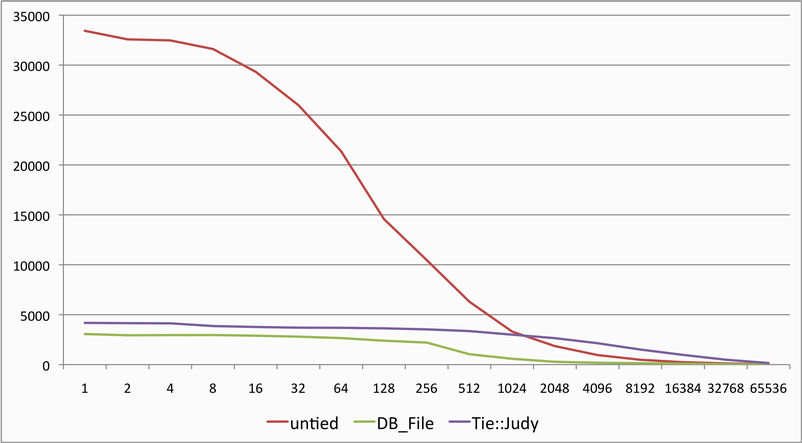
いまさらベンチマークにして説くまでもない。その目で見届けてあげるといい。長大キーを前にして、ハッシュがどこまでやれるか。
予想どおり、キーが長くなるにつれ性能はどんどん劣化していきます。一行の長さとしてよく出てきそうな二桁台の後半は、単語の長さとして適当な一桁台-二桁前半の半分まで落ちています。これが216byteともなると、一桁台では30000/s以上だったのが何と50/sを切っています。
もう関数にも頼らない
しかしよく考えると、「その文字列に対応するデータを別の文字列に対応するデータで上書きしない」ようにするために、全文字列を舐める必要があるのでしょうか? strcmp() ですらそんなもったいないことしてませんよね?たとえばa…とz…だったら、最初の文字を見るだけでこれは別物と気づきます。本当に調べなければならないのは先頭が重複する文字分--共通接頭辞(common prefix)までで、そこから先は残った接尾辞(suffix)を比較するだけでキーが同じか判定できるはずですよね?

本blogでも何回か取り上げたTrieが、まさにそういう構造になっています。計算しない。ただ文字(実はunsigned byteな整数)を添字とするポインターをたぐっていくだけ。C++ の std::mapの実装でも用いられる二分探索木のような比較もなし。同じ"O(1)"でもずっと高速。Encode.pmの文字コード変換表も実はTrieです。
ただしランダムアクセスしようとすると素朴な実装ではずいぶんとかさばるものとなってしまいますし、簡潔データ構造にすると、後からキーと値のペアを追加したり削除したりしにくくなったり、実装がさらに大変になったりするというわけで、ハッシュテーブルのような万能選手としては見なされていまんでした。
ところがなんということでしょう。本blogでも試したことがあるJudyが、実はTrieだったのです。
Judy array - Wikipedia, the free encyclopediaRoughly speaking, it is similar to a highly-optimised 256-ary trie data structure.[2] To make memory consumption small, Judy arrays use over 20 different compression techniques to compress trie nodes.
当時は「どう使う」止まりで、「どうやって」まで考えが及ばなかったことがばればれです。
で、実は先ほどのグラフにも、そのPerl用のバインディングであるTie::Judyで試してみた結果が乗っています。Tieの巨大なオーバーヘッドに関わらず、2048 bytes 以上のキーではPerlネイティブなHashより高速です。

1byteのキーの場合を1とした場合の性能比をグラフにしてみると、Judyが長大キーに強いことが見てとれます。2048 byteの時点でperlでは1割を切っているのに対し、まだ6割以上の性能を維持しているのです。JudyがTrieであればこれも納得がいくところです。
Tie::Judyはまだバグあり必要な機能なし(eachできん!)だったりでとてもプロダクションレベルではないのですが、ラッパー経由ではなく言語レベルで組み込めばハッシュを置き換えることも可能なのではと思えて来ました。Give trie a try!
トライ木 - Wikipediaトライ木はハッシュテーブルの代替としても使用でき、次のような利点がある:
- 理論上、平均検索性能は同じだが、実測するとトライ木の方が早い。
- ハッシュテーブルの検索の最悪時間は O(N) である。
- キーの衝突(コリジョン)が発生しない。
- ハッシュ関数を用意する必要がない。
- トライ木ではキーの辞書順を自動的に生成できる。
Judyでもなんでもいい。今日までハッシュ値計算と戦ってきたみんなを、連想配列を信じたプログラマーを、私は泣かせたくない。
Dan the Collection of Hashed Interests with Too Many Collisions
Benchmark Source
#!/usr/bin/env perl
use strict;
use warnings;
use Benchmark qw/:all/;
my $modtie = shift;
eval qq{require $modtie} if $modtie;
die $@ if $@;
my $tests = {};
my @chars = 0x20..0x7e;
for my $i ( 0 .. 16 ) {
my $len = 2**$i;
my @keys = map { chr($_) x $len } @chars;
$tests->{$len} = $modtie
? sub {
tie my %hash => $modtie;
@hash{@keys} = @chars;
tied(%hash)->CLEAR; # or memory leaks as of Tie::Judy 0.05
}
: sub {
my %hash;
@hash{@keys} = @chars;
};
}
print "#### MODULE = ", $modtie || 'NONE', " ####\n";
cmpthese timethese 0 => $tests;


このブログにコメントするにはログインが必要です。
さんログアウト
この記事には許可ユーザしかコメントができません。